


El archivo robots.txt es un fichero de texto muy importante a la hora de saber qué tiene que indexarse de una web en los motores de búsqueda. Este archivo dicta una serie de pautas de indexación y comportamiento para que los robots accedan o no a determinada información. Cuando los robots llegan a nuestra web querrán analizar todo tipo de información, pero si nosotros decimos dónde no tiene que acceder, nos respetarán y pasarán por alto esa parte de nuestra web.

¿Por qué queremos evitar que no se indexe toda nuestra web?
A nivel SEO y posicionamiento orgánico el archivo robots.txt tiene una gran importancia. Habrá secciones privadas de nuestra web que no convenga que sean indexadas. De este modo se puede hacerse de dos maneras:
-
Bloqueo a través de etiqueta meta robots: En este caso la página que incluya esta etiqueta no será indexada, pero el buscador accederá a su información y tendrá en cuenta los enlaces que pueda tener hacia otras páginas. De esta forma se está transmitiendo valor a esos enlaces.
-
Bloqueo mediante el archivo Robots.txt: Aquí, el archivo es centralizado para el control de la entrada de los robots. La página no será rastreada ni indexada. En este caso será invisible para el motor de búsqueda, tanto la página como los enlaces que contenga.
Nos vamos a centrar en el archivo Robots.txt en esta ocasión. Cuando un robot llega a tu web, lo primero que hace es buscar si existe algún archivo de robots.txt, antes de entrar a ninguna otra página, y seguirán las pautas establecidas si es que existen. A través del fichero podremos detener el acceso a determinadas páginas, pero también podemos elegir si queremos que haya un buscador que no nos encuentre. A través del archivo podemos configurar el acceso de forma personalizada.
Posibles motivos por los que queremos denegar el acceso a ciertas secciones de nuestra web
-
Tenemos contenido duplicado, por ejemplo, versiones para imprimir que no queremos que aparezcan.
-
Cuando queremos que determinadas partes de la web no aparezcan dentro de los buscadores.
-
Bloquear el acceso a ciertos archivos de código.
-
Bloquear directorios completos de archivos alojados en nuestro servidor.
-
Indicar la localización del mapa de sitio o SiteMap.
-
Evitar sobrecargas de servidor, ya que a través de comandos que explicaremos más adelante podremos controlar las peticiones de alguno de los robots y evitar saturaciones.
¿Cómo crear un fichero de Robots.txt?
El archivo Robots.txt se caracteriza porque siempre va en la raíz del sitio web. No es algo que haya que tener de forma obligatoria, simplemente lo crearemos si queremos que algunas páginas sean invisibles para Google o cualquier otro motor de búsqueda.
Si optamos por generar el fichero, únicamente debemos crear un documento de texto con el nombre de “robots.txt” y éste lo vamos a subir a nuestro dominio. La estructura de la url deberá ser: "http://www.nuestrodominiodeejemplo/robots.txt".
A través de Notepad o bloc de notas podremos crear el documento y subirlo al FTP de nuestra web. A partir de aquí existirán muchos comandos que darán las pautas a los robots para saber si pueden entrar o no.
¿Qué comandos podemos utilizar en un archivo Robots.txt?
-
User-agent: Nos indica a quién va dirigido el mandato. Como ya hemos comentado antes se puede dirigir a todos los robots (*), podemos dirigirnos a una parte, incluso prohibirle el paso a los robots un motor de búsqueda específico.
-
Disallow: Vamos a denegar la entrada de los robots a nuestra web. Como lo que queremos es denegar a determinadas secciones de la web, debemos de especificar la sección que sea. En el ejemplo que pongo a continuación veremos cómo se especifica.
-
Allow: En este caso estaremos permitiendo la entrada a nuestra web. Suele utilizarse cuando una parte del Disallow nos interesa que sí sea indexado. En esta caso estaremos sobrescribiendo la pauta del Disallow de forma parcial.
-
Crawl-delay: Con este comando especificaremos cuanto tiempo debe esperar el robot para pasar de un fichero a otro. Normalmente se utiliza para evitar las sobrecargas del servidor.
-
Sitemap: Con el Sitemap vamos a indicar la ruta de nuestro mapa de sitio XML. De esta forma estaremos facilitando el trabajo a Google a la hora de indexar nuestro Sitemap.
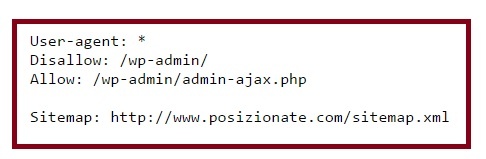
Este sería un ejemplo de la web de Posizionate, si nos metemos en el archivo Robots.txt. En este caso, el asterisco nos informa que se está dirigiendo a todos los robots. El termino Disallow nos informa que los robots no tienen acceso a la parte de administrador. Sin embargo una parte de ese índice sí que puede tener acceso, debido al Allow. Recuerda que a pesar de haber desautorizado la entrada “/wp-admin/”, estamos desautorizando la prohibición a una parte de esa sección, que en este caso es “/wp-admin/admin-ajax.php” En cuanto a Sitemap, estamos indicando la ruta para que los robots puedan indexar de forma más fácil nuestro mapa de sitio.
Tenemos que andarnos con mucho ojo con el archivo Robots.txt que generemos, ya que un fallo puede suponer que estemos diciendo a los robots que no pueden indexar nada de nuestra página, y entonces tendremos un problema bastante serio, ya que seremos invisibles para los buscadores y no existiremos.
